Climbing out of the Docker traffic control pitfall...
Recently I went on-site to diagnose a problem that network communication between Docker containers were obstructed having installed our software. After coming off the diagnostic session, I searched on Internet and was astonished by the barrenness of articles and blogs digging further into such kind of problem. Since I've really gained something to say about it, I decided to write such blog to share them. Hopefully anyone read this article could be enlightened by the blog.
The client complained when our software was running, the Docker container would be incapable of communicating with each other, causing process inside container to exit with error message "No route to host", and container itself to restart over and over again. The communication would restore nearly instantly after stopping our software. By simply toggling on and off certain networking related modules, the suspect was quickly narrowed down to the traffic control module inside our software, breaking its own cover when it attempted to apply traffic control policy over Docker network interface.
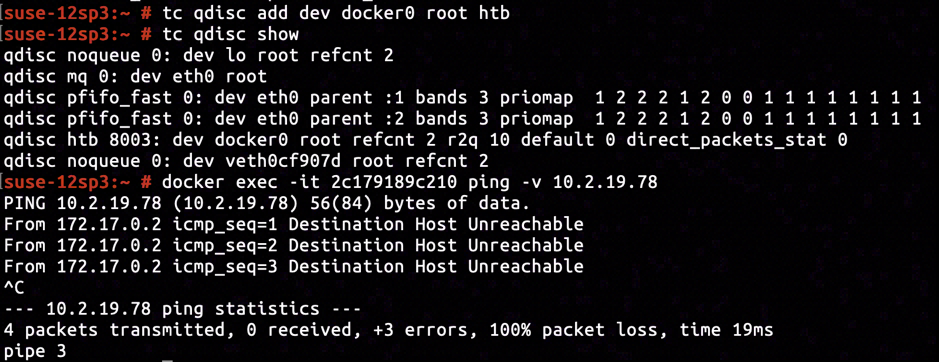
This problem can even be reproduced with no uncertainty when proper environment of reproduction has been set up. We've installed a Linux distro of SUSE12 SP3 (Kernel version 4.4.73-5-default) for reproducing, on which an ethernet interface with IP address 10.2.19.78 was plugged in, and a Docker container was started. The docker container was assigned ID 2c179189c210, and was using a bridged mode container network.
By issuing tc qdisc add dev docker0 root htb we've added a traffic control policy of Hierarchical Token Bucket (abbreviated HTB) to the Docker interface. Checking the connectivity by pinging from inside the container, using docker exec -it 2c179819c210 ping -v 10.2.19.78, we constantly received error message "Destination Host Unreachable", rendering the connectivity between container and host was broken.
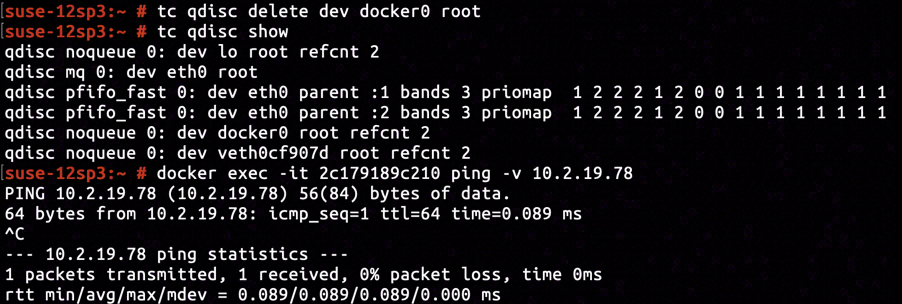
After issuing tc qdisc delete dev docker root0 to remove the previously added traffic control policy, we found the connectivity was fixed instantly.
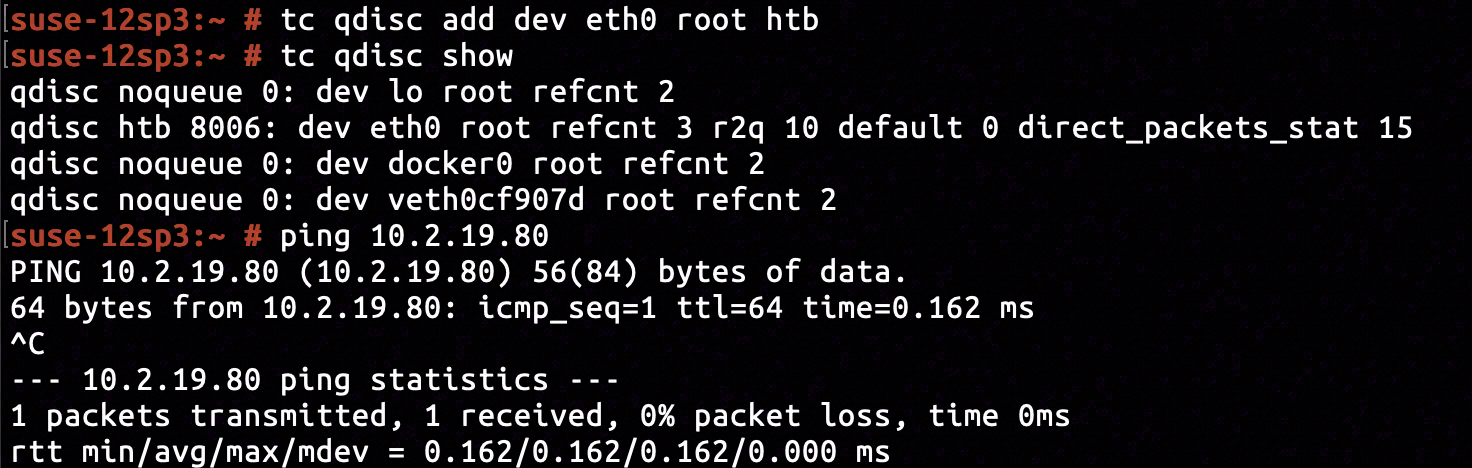
The same anomaly was not applicable to non-Docker network interfaces. By issuing tc qdisc add dev eth0 root htb we've added a HTB policy to egress ethernet interface of the host machine. Nothing abnormal happened when we attempted to ping another online machine 10.2.19.80.
So single command of adding traffic control policy might not be so simple as it seems to be. Orbiting the command and its outcome, unsettling suspicions popped out and bewildered me:
- How could it be dedicated to communication with Docker interfaces enrolled, and without any visible effect when applied to true ethernet interfaces?
- We've not modified routing table yet, how could it affect routing table (inferred from "
Destination Host Unreachable")? - One step further from question 2, there's no explanation for the instant recovery after removing the traffic control policy.
- What's the decent way to add traffic control policy to Docker interfaces? Why should Linux kernel introduce such difference? Should user care about the difference when they want to impose traffic control policy, or should it be some kind of kernel bug (though no Guru Meditation screen pops out)?
Without settling and giving answers to suspicions above, there'll never be sound or working solution.
In this article, we will explore the solution space in a top-down manner, breaking down components of Linux networking module, and giving answers to suspicions above by analysis and evidences.
Impassable Passage
When the container is configured to use bridged mode network, a unique ethernet virtual ethernet interface will be allocated for it, as well as a unique network namespace into which processes in container should be emplaced.
In this article, to simplify further operations and explanations, we emplaced current interactive shell into container's network namespace, and assumed all command executed without explicit indication to be inside the namespace.
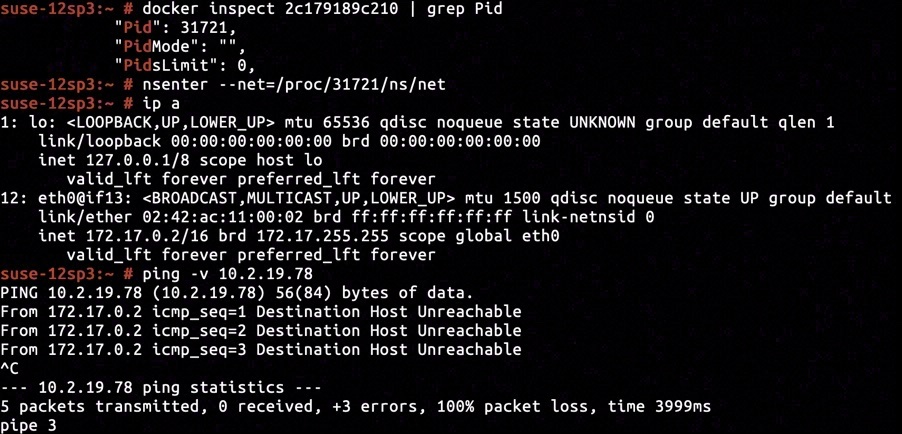
The container's network namespace comprised of a loopback interface lo and a virtual ethernet interface eth0@if13 with IP address configured to be 172.17.0.2. Pinging the host ethernet address would we be ponged with "Destination Host Unreachable", just identical to what we've seen when issuing docker exec 2c179819c210 ping -v 10.2.19.78 outside the container.
It worths our attention that the ICMP request was responsed by the virtual ethernet interface eth0@if13, which was an egress interface of the container's network namespace. So the ICMP request packet had even not yet got a chance to exit the network namespace, it was intercepted by eth0@if13 which judged there was no passable passage to the destination.
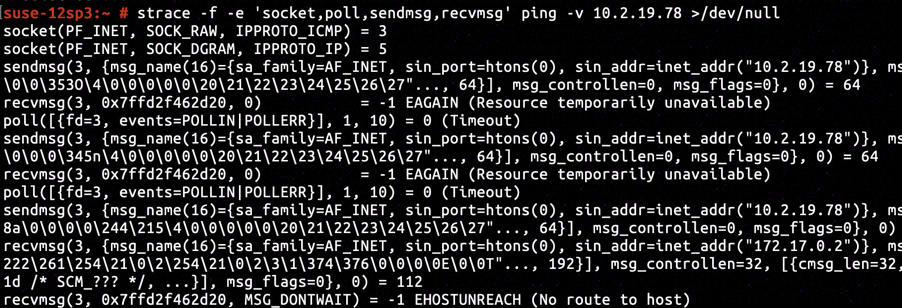
By tracing system calls during ping's execution with strace, we found out that socket created a raw socket dedicated to ICMP protocol, operating on the raw socket sendmsg initiated a ICMP ping request to destination with addess 10.2.19.78, and finally recvmsg received the error EHOSTUNREACH generated by eth0@if13.
However sendmsg and recvmsg are two independent system calls, making it hard to trace and explain, and thus are not suitable for our exploration and analysis to start with.
Instead we started with connect system call. When a application invokes connect to initiate a connection with remote host, using a active TCP socket created by socket system call in blocking mode, it will be blocked until the underlying TCP socket completes the three-way TCP handshake for connection establishing, or unrecoverable errors such as connection timeout and network failure are generated.
// gcc conntest.c -o conntest
#include <arpa/inet.h>
#include <sys/socket.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main() {
int fd = socket(AF_INET, SOCK_STREAM, 0);
if(fd < 0) {
perror("socket");
return -errno;
}
struct sockaddr_in addr;
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(443);
addr.sin_addr.s_addr = inet_addr("10.2.19.78");
if(connect(fd, (struct sockaddr*)&addr, sizeof(addr)) < 0) {
perror("connect");
return -errno;
}
close(fd);
return 0;
}
We've written a snippet of code to attempt TCP connection with 10.2.19.78:443. The code was compiled into conntest program and executed. The execution ended after blocked for around 3 seconds, and thereafter the perror formatted the received -EHOSTUNREACH as No route to host error, analogous to outcome that our client complained about.
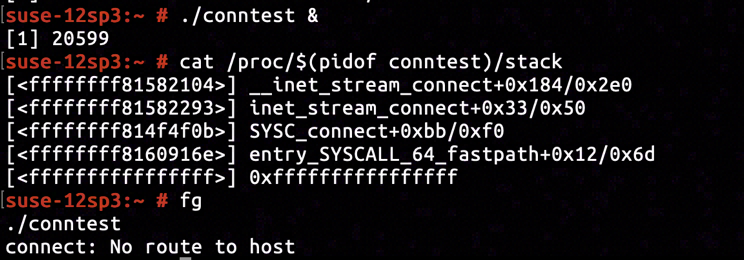
The call stack when conntest was blocked by connect inside kernel space was retrieved using cat /proc/$(pidof conntest)/stack. Conjuncted with kernel image's disassembly we knew connect system call is blocked when __inet_stream_connect invoked inet_wait_for_connect on line net/ipv4/af_inet.c:618.
static inline int sock_error(struct sock *sk)
{
...
err = xchg(&sk->sk_err, 0);
return -err;
}
int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr,
int addr_len, int flags)
{
struct sock *sk = sock->sk;
...
switch (sock->state) {
...
case SS_UNCONNECTED:
...
err = sk->sk_prot->connect(sk, uaddr, addr_len);
if (err < 0)
goto out;
sock->state = SS_CONNECTING;
...
}
... // if (...) {
if (!timeo || !inet_wait_for_connect(sk, timeo, writebias))
goto out;
err = sock_intr_errno(timeo);
if (signal_pending(current))
goto out;
}
if (sk->sk_state == TCP_CLOSE)
goto sock_error;
sock->state = SS_CONNECTED;
err = 0;
out:
return err;
sock_error:
err = sock_error(sk) ? : -ECONNABORTED;
sock->state = SS_UNCONNECTED;
if (sk->sk_prot->disconnect(sk, flags))
sock->state = SS_DISCONNECTING;
goto out;
}
We cropped crucial execution flow associated with -EHOSTUNREACH out of __inet_stream_connect. The followed steps will be taken before -EHOSTUNREACH is returned to the application:
- Initiate TCP three-way handshake with destination by calling
sk->sk_prot->connectfunction pointer. - Enqueue current task into wait queue by calling
inet_wait_for_connect. - TCP handshake could not be completed due to
-EHOSTUNREACHerror, the code will be assigned tosk->sk_errand previously enqueued task will be waken. - Waken task is executed,
sock_errorswaps out the-EHOSTUNREACHerror, and delivers it to the application.
By watching out for who modified sk->sk_err using perf, capturing the call stack when assignment happens, we will be able to track down the origin of -EHOSTUNREACH.
The sk object holding sk->sk_err is embedded as sock->sk field. First the socket system call initializes sock and sk objects, embeds sk into sock->sk, puts it into a file and associates the file with file descriptor so that application could refer to them. Then connect system call will retrieve sock from the file specified by file descriptor, and retrieve sk by derefering sock->sk. So when we have retrieved kernel address of sk, we will be capable of inserting hardware breakpoint for memory-write on sk->sk_err, capturing the call stack meantime.
We are not alone invoking socket system call for creating socket. To effectively trace the sock object created by conntest, we will need to retrieve the PID of conntest and set it as a filter before conntest invokes socket system call.
So we added extra lines of code code before invoking socket and connect system calls, waiting for us to retrieve information, setup certain filter and press Enter to continue on execution.
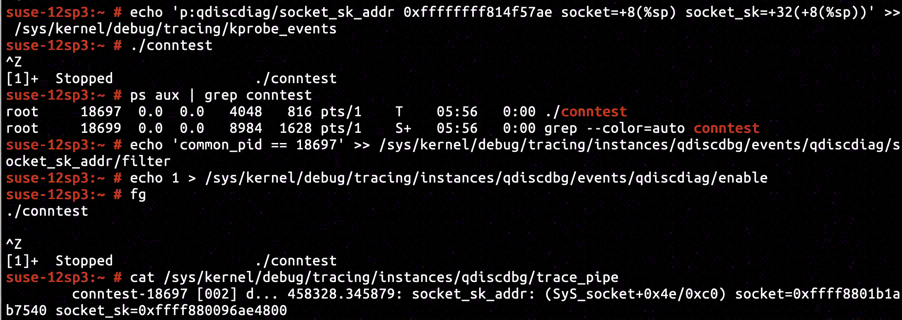
After inspecting the kernel image's disassembly, we've located the instruction right after sock_create completes on line net/socket.c:1234 to be at address ffffffff814f57ae. The pointer of sock object is filled into the space with offset +0x8 relative to current stack frame base, after the sock_create returns with success. The offset of sock->sk relative to sock is +0x32. Having inserted KProbe tracepoint on ffffffff814f57ae and set up proper KProbe retrieval command, we've determined that the address of sock->sk to be ffff880096ae4800.
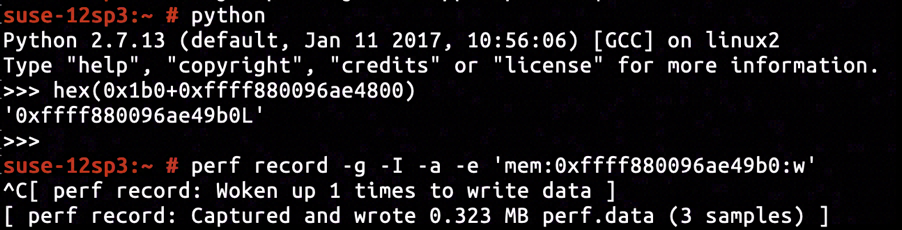
According to the disassembly of __inet_stream_connect, the offset of sk->sk_err relative to sk is +0x1b0. So the address to insert hardware breakpoint monitoring assignment to sk->sk_err is ffff880096ae49b0.
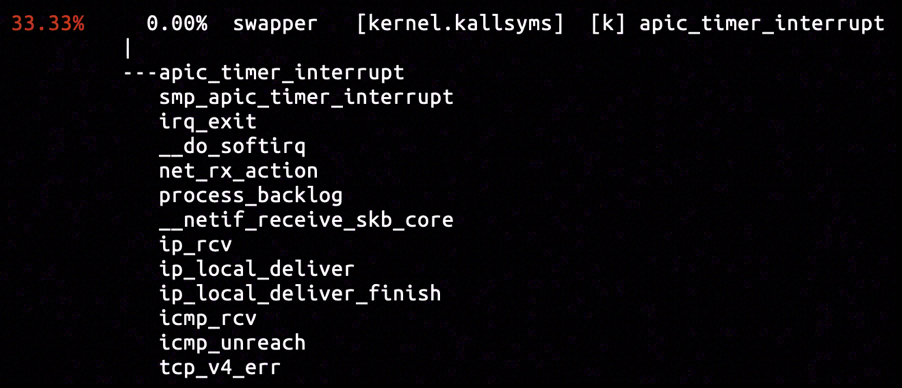
The inserted hardware breakpoint captured three samples, and the only sample as is shown above assigned EHOSTUNREACH to sk->sk_err. The call stack is included in a NAPI processing stack. Inferring from the icmp_rcv function popped up on the call stack, an ICMP packet holding "Destination Host Unreachable" was received and processed, and terminated the ongoing TCP three-way handshake.
The destination IP referred to a virtual ethernet interface on the same host (rather than another machine on network), so the ICMP packet might have been generated on the current operating host. We will try out luck to capture the call stacks associated with icmp_send.
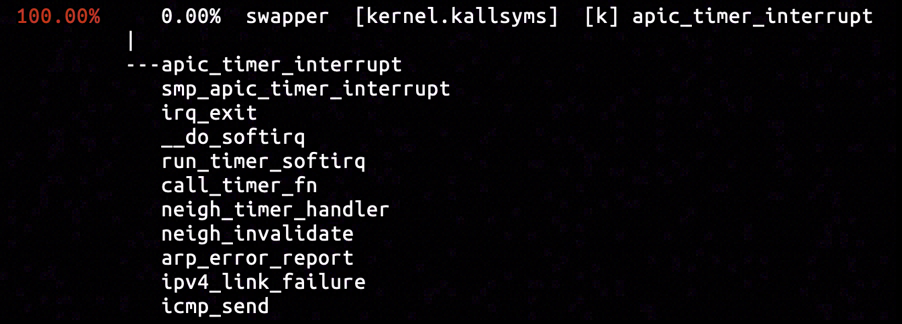
By inserting hardware breakpoint in the entrypoint of icmp_send function, we captured the only sample calling icmp_send. It was included in a clock interrupt processing stack. Judging from the name of functions in the call stack, some kind of expiration occurred so that neigh_timer_handler believed the destination host unreachable, on the other side of the call chain, icmp_send reports such unreachable state of the network linkage, interrupting on-going communication over the linkage.
As conclusion for this chapter, we've found out the error "Destination Host Unreachable" received by the application is originated from function neigh_timer_handler and neigh_invalidate, which are part of Linux neighbouring subsystem. The application added itself to some kind of notification collection in neighbouring subsystem, and started some timer. The operation adding traffic control policy to Docker interface caused the timer to expire with timeout, and upon expiration the neighbouring subsystem notified application in the notification collection with "Destination Host Unreachable" error.
Bad Neighbour
It's getting interesting when Linux neighbouring subsystem comes in and holds up a great sign with "look at me" written on it. The modification of traffic control policy affects neighbouring subsystem rather routing table. And it remains a mystery why deleting the traffic control policy will instantly recover the normal operation of subsystem.
I am sure that all readers are not so acquainted with Linux neighbouring system, and especially confused about the role that the subsystem is playing inside Linux networking's scheme, and what sending a TCP payload has to do with the subsystem. For everyone's better understanding about this article and the subsystem, let's plot out the links and relationships between the subsystem and its superior protocols (TCP, IP, etc.).
static void neigh_invalidate(struct neighbour *neigh)
__releases(neigh->lock)
__acquires(neigh->lock)
{
...
while (neigh->nud_state == NUD_FAILED &&
(skb = __skb_dequeue(&neigh->arp_queue)) != NULL) {
write_unlock(&neigh->lock);
neigh->ops->error_report(neigh, skb);
write_lock(&neigh->lock);
}
...
}
static void neigh_timer_handler(unsigned long arg)
{
...
if ((neigh->nud_state & (NUD_INCOMPLETE | NUD_PROBE)) &&
atomic_read(&neigh->probes) >= neigh_max_probes(neigh)) {
neigh->nud_state = NUD_FAILED;
notify = 1;
neigh_invalidate(neigh);
goto out;
}
...
}
We will begin with neigh_timer_handler and neigh_invalidate. Both of them are defined in net/core/neighbour.c. The neigh_timer_handler will check neigh->nud_state for either NUD_INCOMPLETE or NUD_PROBE flag, and enter the branch of invoking neigh_invalidate to notify about unreachability when either flag is present and condition atomic_read(neigh->probes) >= neigh_max_probes(neigh) is met.
For me, it feels like that the flags of NUD_INCOMPLETE or NUD_PROBE in neigh->nud_state is set as an indicator, by who arms the timer for the checking in neigh_timer_handler. So let's concentrate on finding out who modifies the neigh->nud_state.

By inserting KProbe capturing the address of neigh into neigh_invalidate, we knew that the operated neigh object was located at ffff8801b106cc00.
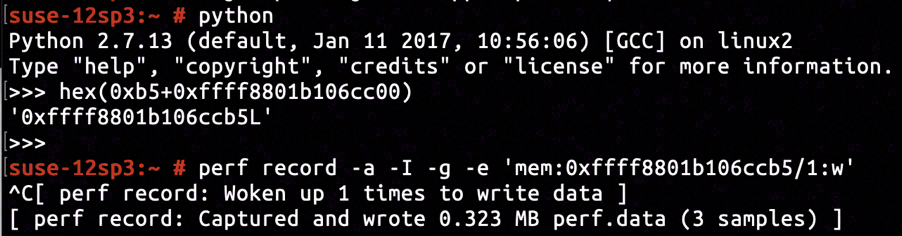
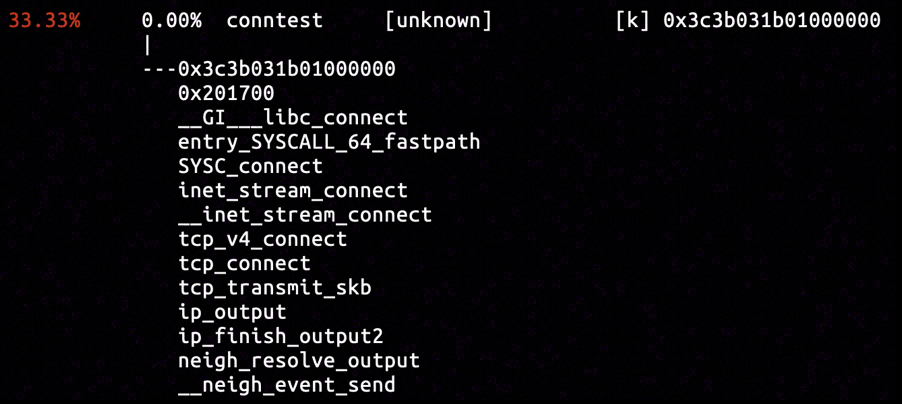
By inspecting the disassembly of neigh_invalidate, we knew neigh->nud_state occupies a 1-byte space offsetted +0xb5 relative to neigh. And by inserting hardware breakpoint for memory-write using perf, we were able to capture assignments to neigh->nud_state.
Three samples were captured in total by the hardware breakpoint, and the one shown above had strong affinity with the connect system call. The call stack departed from the connect system call, visiting tcp_transmit_skb of transport layer and ip_finish_output2 of network layer, and finally arrived at the neigh_resolve_output function.
static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb)
{
...
rcu_read_lock_bh();
nexthop = (__force u32) rt_nexthop(rt, ip_hdr(skb)->daddr);
neigh = __ipv4_neigh_lookup_noref(dev, nexthop);
if (unlikely(!neigh))
neigh = __neigh_create(&arp_tbl, &nexthop, dev, false);
if (!IS_ERR(neigh)) {
int res = dst_neigh_output(dst, neigh, skb);
rcu_read_unlock_bh();
return res;
}
...
}
The ip_finish_output2 first lookups the nexthop for routing to destination IP address ip_hdr(skb)->daddr in routing table rt, then it invokes __ipv4_neigh_lookup_noref to find the neighbour table item neigh associated with nexthop, and finally invoke dst_neigh_output to pass the responsibility of transmission to neighbouring system. The dst_neigh_output is inlined and would finally invokes neigh_resolve_output after getting through a series of cascaded function calls.
int neigh_resolve_output(struct neighbour *neigh, struct sk_buff *skb)
{
int rc = 0;
if (!neigh_event_send(neigh, skb)) {
int err;
struct net_device *dev = neigh->dev;
unsigned int seq;
if (dev->header_ops->cache && !neigh->hh.hh_len)
neigh_hh_init(neigh);
do {
__skb_pull(skb, skb_network_offset(skb));
seq = read_seqbegin(&neigh->ha_lock);
err = dev_hard_header(skb, dev, ntohs(skb->protocol),
neigh->ha, NULL, skb->len);
} while (read_seqretry(&neigh->ha_lock, seq));
if (err >= 0)
rc = dev_queue_xmit(skb);
else
goto out_kfree_skb;
}
out:
return rc;
out_kfree_skb:
rc = -EINVAL;
kfree_skb(skb);
goto out;
}
When neigh_event_send returns 0, the main body of neigh_resolve_output will be executed, fetching hardware address (e.g. MAC address) from neigh->ha, filling data link layer PDU (e.g. ethernet frame) of skb, and finally enqueuing skb into device transmit queue by invoking dev_queue_xmit.
It's obviously that without valid hardware address stored inside neigh->ha, the data link layer PDU could not be completed for specified skb, which therefore could not be transmitted. As we known for IPv4 address family, ARP protocol serves as the hardware address querying protocol, asking other devices on the same subnet MAC address associated with certain IPv4 address.
static inline int neigh_event_send(struct neighbour *neigh, struct sk_buff *skb)
{
unsigned long now = jiffies;
if (neigh->used != now)
neigh->used = now;
if (!(neigh->nud_state&(NUD_CONNECTED|NUD_DELAY|NUD_PROBE)))
return __neigh_event_send(neigh, skb);
return 0;
}
int __neigh_event_send(struct neighbour *neigh, struct sk_buff *skb)
{
...
bool immediate_probe = false;
...
if (!(neigh->nud_state & (NUD_STALE | NUD_INCOMPLETE))) {
if (NEIGH_VAR(neigh->parms, MCAST_PROBES) +
NEIGH_VAR(neigh->parms, APP_PROBES)) {
unsigned long next, now = jiffies;
atomic_set(&neigh->probes,
NEIGH_VAR(neigh->parms, UCAST_PROBES));
neigh->nud_state = NUD_INCOMPLETE;
neigh->updated = now;
next = now + max(NEIGH_VAR(neigh->parms, RETRANS_TIME),
HZ/2);
neigh_add_timer(neigh, next);
immediate_probe = true;
... // } else { ... }
... // }
out_unlock_bh:
if (immediate_probe)
neigh_probe(neigh);
...
}
The behaviour of neigh_event_send is checking the validity of neigh->ha inside a neighbour table item neigh, and initiating a hardware address probing with protocols like ARP if neigh->ha is currently invalid, which is mostly completed by its internal implementation __neigh_event_send.
When a hardware probing is required, the __neigh_event_send will mark the neigh->nud_state as NUD_INCOMPLETE, arm a timer to invoke neigh_timer_handler for retransmission or timeout handling, and finally invoke neigh_probe for probing hardware address with proper probing protocol.
By now we've already plotted some links and relations between neighbouring subsystem and its upper level protocols: when a destination host is specified, network layers finds the nexthop the reach the destination, while a neighbour table item stores the hardware address corresponding to each nexthop. The subsystem itself plays the role of completing data link layer PDU for each skb pending for transmission.
The __neigh_event_send inside the call stack captured by perf was a distress constantly emitting a signal that TCP handshake was obstructed by the absense of the hardware address of the nexthop.
static const struct neigh_ops arp_generic_ops = {
.family = AF_INET,
.solicit = arp_solicit,
...
};
static const struct neigh_ops ndisc_generic_ops = {
.family = AF_INET6,
.solicit = ndisc_solicit,
...
};
static void neigh_probe(struct neighbour *neigh)
__releases(neigh->lock)
{
...
if (neigh->ops->solicit)
neigh->ops->solicit(neigh, skb);
...
}
The neigh_probe invokes specific probing function stored in neigh->ops->solicit to fetch hardware address for current neighbour table item.
Each neighbour table item is associated with certain network address family. Each network address family has their own probing protocols and thus probing function sending message of that protocol. The IPv4 address family uses arp_solicit to send ARP message for address probing, while the IPv6 address family uses ndisc_solicit to send NDP message instead.
As we were connecting to an IPv4 address in our experiment, the next function to take a look into should be arp_solicit.
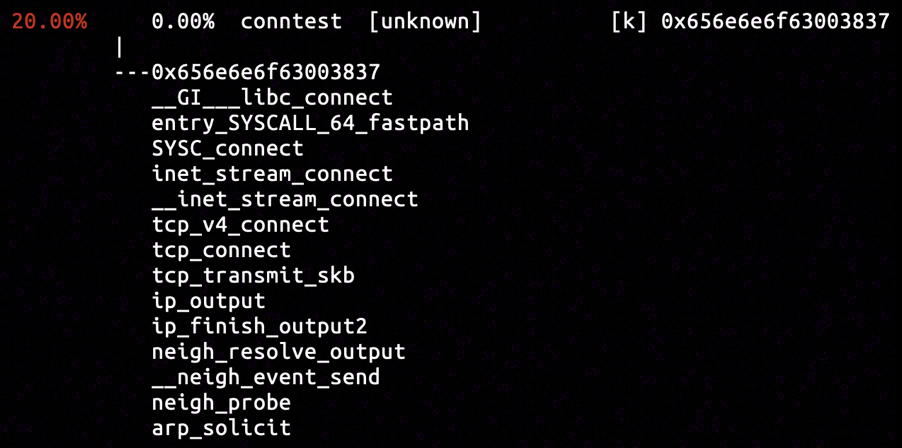
By inserting hardware breakpoint in the entrypoint of arp_solicit, we captured the sample of call stack concatenating all functions we've analyzed in neighbouring subsystem, to the call stack originated from connect system call. It is a validation for our analysis by now.
static void arp_send_dst(int type, int ptype, __be32 dest_ip,
struct net_device *dev, __be32 src_ip,
const unsigned char *dest_hw,
const unsigned char *src_hw,
const unsigned char *target_hw,
struct dst_entry *dst)
{
struct sk_buff *skb;
/* arp on this interface. */
if (dev->flags & IFF_NOARP)
return;
skb = arp_create(type, ptype, dest_ip, dev, src_ip,
dest_hw, src_hw, target_hw);
if (!skb)
return;
skb_dst_set(skb, dst_clone(dst));
arp_xmit(skb);
}
static void arp_solicit(struct neighbour *neigh, struct sk_buff *skb)
{
...
arp_send_dst(ARPOP_REQUEST, ETH_P_ARP, target, dev, saddr,
dst_hw, dev->dev_addr, NULL, dst);
}
Both arp_solicit and arp_send_dst are defined in net/ipv4/arp.c. The arp_solicit gathers the information like source IP, and fires the transmission of ARP request message (with ARP operation code ARPOP_REQUEST), while arp_send_dest formats the ARP message specified in parameter as skb by invoking arp_create, and sets it on transmission by invoking arp_xmit.
static int arp_xmit_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
return dev_queue_xmit(skb);
}
void arp_xmit(struct sk_buff *skb)
{
/* Send it off, maybe filter it using firewalling first. */
NF_HOOK(NFPROTO_ARP, NF_ARP_OUT,
dev_net(skb->dev), NULL, skb, NULL, skb->dev,
arp_xmit_finish);
}
The arp_xmit invokes Netfilter hook to walk through ARP protocol Netfilter chain, filtering and modifying the ARP message, and then invokes dev_queue_xmit to enqueue it into the transmit queue of egress interface bounding for nexthop.
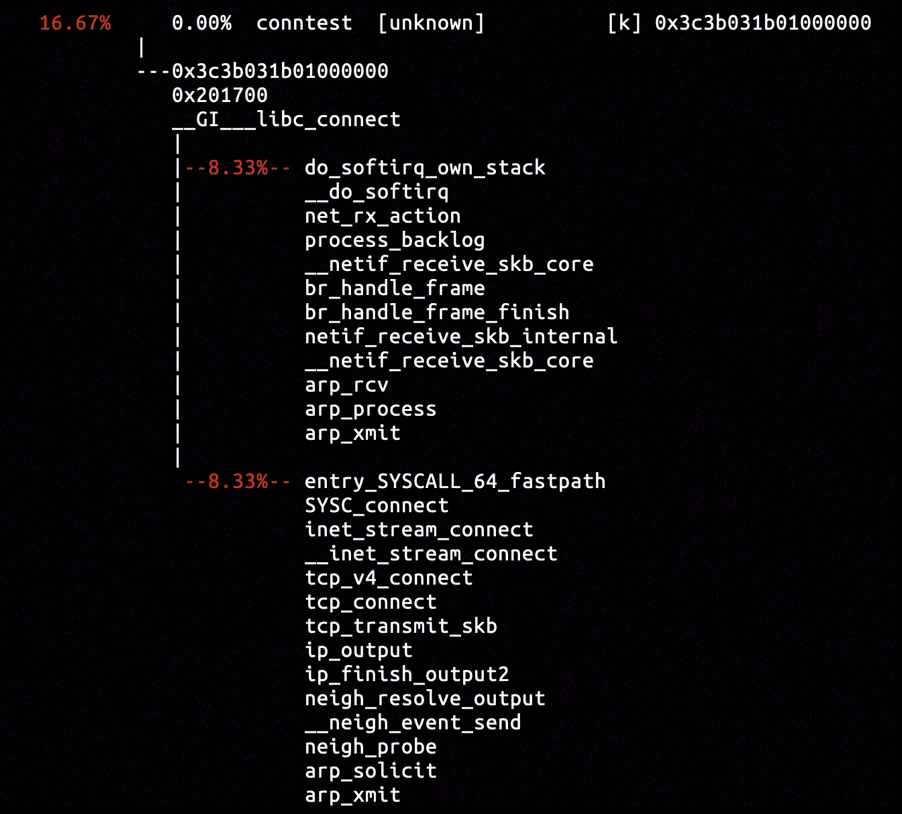
By inserting hardware breakpoint in the entrypoint of arp_xmit function, we captured samples of call stacks including the previously analyzed arp_solicit and the unseen arp_process. It is obvious by doing some reading that arp_process was sending out the ARP response message (with ARP operation code ARPOP_REPLY) with hardware address of Docker interface, in response to the ARP request from egress interface in the container.
The captured samples provided evidences for Docker interface's reception of ARP request message from container network and corresponding response with ARP response message. The only remaining possibility is that the all ARP response messages was discarded, preventing neigh->ha in neighbour table item from being filled, and expiring the deadline for neighbour probing.
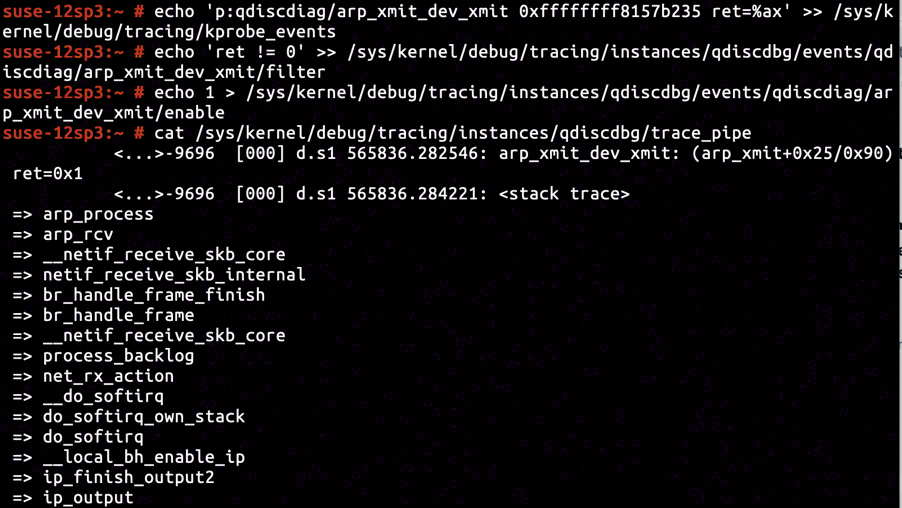
By reading the documentation on net/core/dev.c:3074 for __dev_queue_xmit, we know that 0 will be returned upon successful enqueuing, negative value will be returned otherwise, and positive value will be returned if it is throttled by traffic control algorithm. The dev_queue_xmit is implemented as mere delegation to __dev_queue_xmit(skb, NULL), which means the return value rule for __dev_queue_xmit is equivalently applicable to dev_queue_xmit.
According to the disassembly of arp_xmit, inside the function it returns from invocation to dev_queue_xmit on address ffffffff8157b235. By inserting KProbe for capturing call stacks with return value, and filtering those with non-zero returned, we got arp_process's call stack right matching the set condition. The returned 1 (aka. NET_XMIT_DROP) was a clear indicator for all ARP response message transmitted by Docker interface being discarded by traffic control policy.
static void neigh_probe(struct neighbour *neigh)
__releases(neigh->lock)
{
...
atomic_inc(&neigh->probes);
...
}
static void neigh_timer_handler(unsigned long arg)
{
... // if (...) { ... } else {
/* NUD_PROBE|NUD_INCOMPLETE */
next = now + NEIGH_VAR(neigh->parms, RETRANS_TIME);
... // }
if ((neigh->nud_state & (NUD_INCOMPLETE | NUD_PROBE)) &&
atomic_read(&neigh->probes) >= neigh_max_probes(neigh)) {
neigh->nud_state = NUD_FAILED;
notify = 1;
neigh_invalidate(neigh);
goto out;
}
... // if (...) {
if (!mod_timer(&neigh->timer, next))
neigh_hold(neigh);
... // }
if (neigh->nud_state & (NUD_INCOMPLETE | NUD_PROBE)) {
neigh_probe(neigh);
... // }
...
}
Before roundup for neighbouring subsystem, let's drill a bit futher into the "timeout" for neighbour probing. Each neighbour table item neigh will maintain a counter for currently attempted neighbouring probing (and known as counter for attempted ARP requests in IPv4), which will be atomically incremented by neigh_probe after each completion of probing.
Each time the neigh_timer_handler is invoked (by the expired timer), it will retry another neighbouring probe and reschedule the timer for next retrial, until the probing counter reaches neigh_max_probes(neigh), in which case neigh_invalidate will be invoked for reporting unreachability of the probing neighbour.
Rounding up our previous analysys, a closed circuit around Linux neighbouring subsystem and the disability to establish TCP connection has formed: When a TCP handshake is initiated, the neighbouring subsystem will send an ARP request message to request for hardware address of Docker interface as it is currently vacant. However ARP response messages from Docker interface are dropped by traffic control policy we added. After several retrials, the neighbouring subsystem believes it is impossible to fetch ARP address from Docker interface and finally report the linkage failure, thereby terminates the TCP handshake.
Open Pitfall
Having fully studied the source of "Destination Host Unreachable" error, and the causuality of anomaly inside Linux neighbouring subsystem, we've sifted down the suspicions to why simply adding traffic control policy on Docker interface will cause all traffics to be completely throttled, and shouldn't it be an open pitfall as we are just using traffic control policy's default values while issuing the tc qdisc add command.
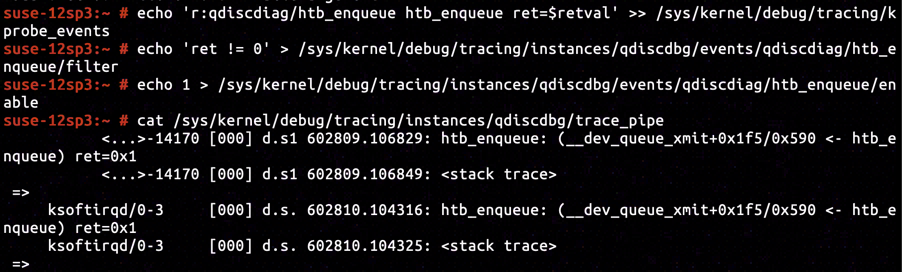
In our experiment, we've set HTB as traffic control policy, whose corresponding enqueuing function is htb_enqueue. By inserting KRetProbe to symbol htb_enqueue, and setting up filter for non-zero return value only, we've confirmed it was the htb_enqueue that dropped the skb and returned NET_XMIT_DROP.
static int htb_enqueue(struct sk_buff *skb, struct Qdisc *sch)
{
...
struct htb_class *cl = htb_classify(skb, sch, &ret);
if (cl == HTB_DIRECT) {
if (q->direct_queue.qlen < q->direct_qlen) {
__skb_queue_tail(&q->direct_queue, skb);
...
} else {
return qdisc_drop(skb, sch);
}
#ifdef CONFIG_NET_CLS_ACT
} else if (!cl) {
...
return ret;
#endif
} else if ((ret = qdisc_enqueue(skb, cl->un.leaf.q)) != NET_XMIT_SUCCESS) {
...
return ret;
// } else { ... }
...
return NET_XMIT_SUCCESS;
}
All return statements and their accompanied conditions have been cropped out from htb_enqueue. All skb entered htb_enqueue will be classified for throttling and discarding by traffic control algorithms. And after classification the destiny of skb falls into cases as is shown below:
- When classified as
HTB_DIRECT, regarding amount currently enqueued item indirect_queueand limitationdirect_qlenfor the queue, it will be either inserted intodirect_queueor discarded. - When cannot be classified (
NULLwill be returned as class), thehtb_classifywould have written the error intoret, it will be discarded and error will be returned. - The
skbwill be enqueued into class specific transmit queue by invokingqdisc_enqueue. If error is returned, theskbwill be discarded and error will be returned. - In all other cases, the
skbwill be successfully enqueued into the Qdisc object and0(aka.NET_XMIT_SUCCESS) will be returned.
According to the disassembly of htb_enqueue, htb_classify has been inlined into htb_enqueue, which means there will be no place for inserting tracepoint to fetch the classification result of htb_classify directly. Instead we should plot our tracing plan deftly according to the way htb_classify is inlined.
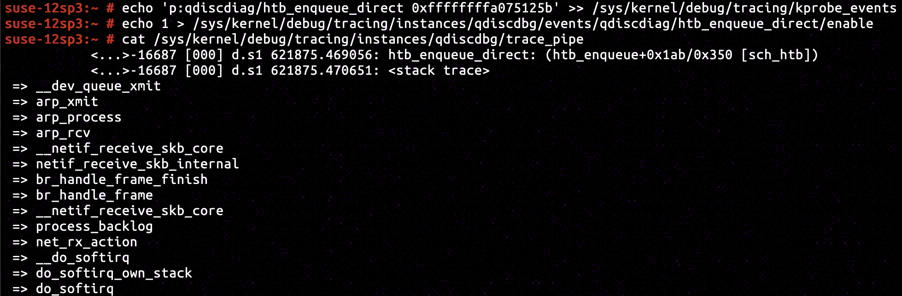
Let's begin with the condition that skb is classified as HTB_DIRECT. According to disassembly of htb_enqueue, instruction at ffffffffa075125b is deemed to be executed when a HTB_DIRECT class skb is to be transmitted.
By inserting KProbe in ffffffffa075125b, we've captured a call stack exactly identical to the one including arp_process, proving that ARP response message was classified as HTB_DIRECT.
Entering the HTB_DIRECT's branch there's a one-way alley ahead, such that amount of currently enqueued item in Qdisc object's direct_queue is greater than or equal to direct_qlen, and NET_XMIT_DROP is returned with skb discarded.
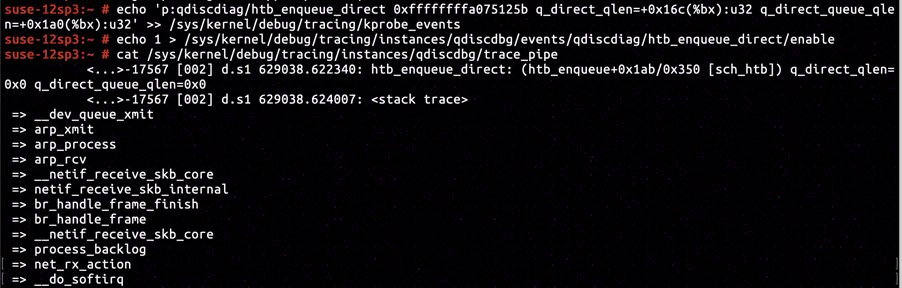
By reading further into the kernel image's disassembly, we've confirmed direct_queue.qlen is offsetted +0x1a0 relative to Qdisc object, while direct_qlen is offseted +0x16c. Resetting the gathering instruction of KProbe inserted in ffffffffa075125b to collect direct_queue.qlen and direct_qlen, we've collected and confirmed both of them to be 0.
It's an obvious anomaly for direct_qlen to be 0, which will lead to all skb classified as HTB_DIRECT to be discarded when HTB is used as traffic control policy.
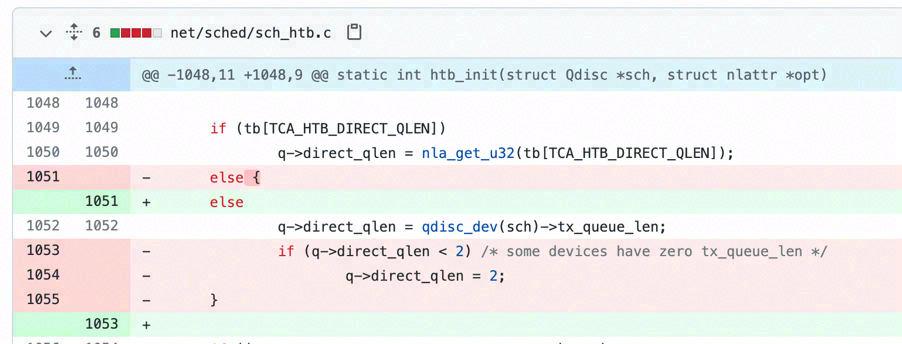
static int htb_init(struct Qdisc *sch, struct nlattr *opt)
{
...
if (tb[TCA_HTB_DIRECT_QLEN])
q->direct_qlen = nla_get_u32(tb[TCA_HTB_DIRECT_QLEN]);
else
q->direct_qlen = qdisc_dev(sch)->tx_queue_len;
...
}
The htb_init initializes Qdisc object for HTB traffic control policy. It receives a RTNetlink message as initialization parameter, and take corresponding value from RTNetlink message if TCA_HTB_DIRECT_QLEN bit has been set. Otherwise tx_queue_len of network interface associated with current Qdisc object will be taken as default value and assigned to direct_qlen.
Obviously we've not explicitly specify direct_qlen in command tc qdisc add dev docker0 root htb when adding traffic control policy to Docker interface. So let's presume it is owing to tx_queue_len attribute of Docker interface set to 0.
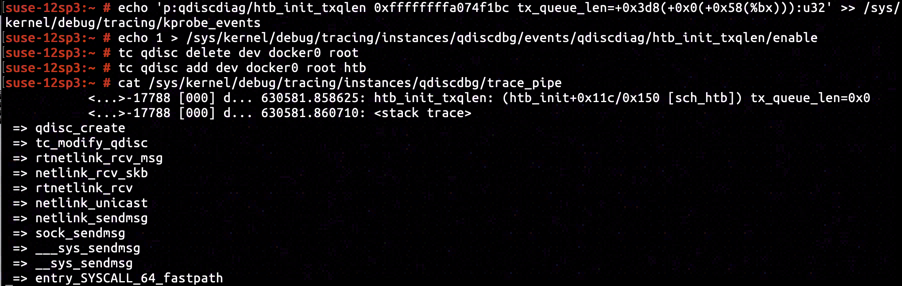
According to the disassembly of htb_init, instruction located at ffffffffa074f1bc is in the branch that tx_queue_len attribute of a network interface is taken and assigned to direct_qlen. By inserting KProbe and capturing tx_queue_len attribute meantime, we've confirmed our previous presumption abot tx_queue_len attribute of Docker interface and the casuality of zero initialized direct_qlen.
I believe someone will simply conclude that it is legible for virtual network interface to have tx_queue_len set to 0, so who configures traffic control policy is obligated to configure proper direct_qlen for them.
So let's have a look at the commit net: sched: drop all special handling of tx_queue_len == 0 introduced into Linux 4.3 mainline. Prior to Linux 4.3, htb_init will automatically handles the zero tx_queue_len from virtual network interface and clamp direct_qlen to at least 2. In spite of being part of Linux network module's refactoring, I think it has undeniably brought a breaking change into Linux 4.4.73 or at least SUSE12 SP3.
Afterword
Actually by toggling on and off networking related modules in our software, I was able to quickly narrowed down that the networking problem is rooted in the HTB traffic control policy we added. And even I was totally not familiar with components in Linux networking modules, I was able to locate the zero assignment when initializing HTB quickly.
But when it comes to giving out solution, I found it hard to explain the outcome of such traffic control policy setting: if all traffic are throttled by HTB traffic control policy, shouldn't the TCP handshake be failed with "Connection Timed Out" rather than "Destination Host Unreachable"?
As I dug deeper to find out explanation for the outcome, I was getting to realize the complexity of the whole problem. Especially when I've seen how the components in Linux networking module were collaborating with each others, I had been doubting whether solution I gave would be sound and work, till I fully studied every branches and leaves related to this problem.
So I decided to write this article out when I felt others could also obtain the feeling of inter-connection between components of Linux networking module. Especially when I broke down every pieces, analyzed their internals and peripherals, and reassmbled them to explain the casualities in the problem, I believe the readers will also gain deeper understanding about Linux networking, or enlightenment about bailing themselves out of similar problems.